Introduction to Subgraphs
Alchemy Subgraphs allow developers to create specialized APIs, aka subgraphs, that define how to ingest, process, and store information from the blockchain, making it easier for apps to query blockchain data.
What is a subgraph?
Subgraphs aggregate application-specific blockchain data for quick access to frontend developers.
Subgraph are exposed to developers via GraphQL APIs, allowing users to query the transaction data happening on their contract in real time. Subgraphs are especially beneficial for developers of complex, custom smart contracts that need to have robust frontend interfaces.
For example, to query all transactions within a single Uniswap v3 liquidity pool over the last 24 hours, Uniswap simply needs to define their schema, index the event data to create the subgraph, and then use the generated GraphQL API to query their subgraph for flexible and efficient blockchain data.
Subgraphs allow developers to filter and sort data based on their needs, letting them extract only the information important to their dapp. Subgraphs also enable more efficient data querying by precompiling and indexing data to speed up the querying process instead of requesting data directly from full nodes or archive nodes. Let's dive in further... 🤿
Why Do We Need Subgraphs & What Problem Do They Solve?
Before we dive deeper into subgraphs, let's first quickly analyze blockchains as data structures. It's helpful to view blockchains simply as databases that are distributed and decentralized. Blockchain databases grow by perpetually adding new blocks, each full of data.
The thing about blockchains is, if viewed as databases, they mainly optimize for:
- Immutability: once data is added, it is really difficult to change that data, so data integrity and historical accuracy is excellent.
- Transparency: all data is public, verifiable and accessible by all.
- Decentralization: blockchains deliver trustless and censorship-resistant server environments for all to use, given there is no central operator.
- Security: all transactions must be independently verified by all network participants, which makes fraudulent transactions virtually impossible.
All of the above properties are awesome for a database to have! They enable applications built on blockchain databases to be really powerful, as developers can lace these properties into the user experience.
However, while blockchains optimize for all of the above properties in great ways, they are not so great for complex data querying. When you need to find a specific piece of data in the blockchain, you need to read through every single block ever and attempt to find your specific piece of data - this is obviously not very efficient! Modern databases (ie, SQL, MongoDB, Postgres DB) are a great solution for complex data querying; subgraphs will help us set up and maintain one such database to help us perform quick and efficient complex data queries to the blockchain.
Say, for example, you are writing a blockchain analytics app and you want to get all of the latest transfers on the $USDC smart contract. Without a subgraph, you'd need to brute force the last 10 or so blocks on the chain, each containing ~150 transactions. In each block, you'd have to check each transaction to see if there was any interaction with the relevant contract address. That's a lot of brute-force searching and that's just for 10 blocks! Here's how a subgraph can help make this query more efficient:
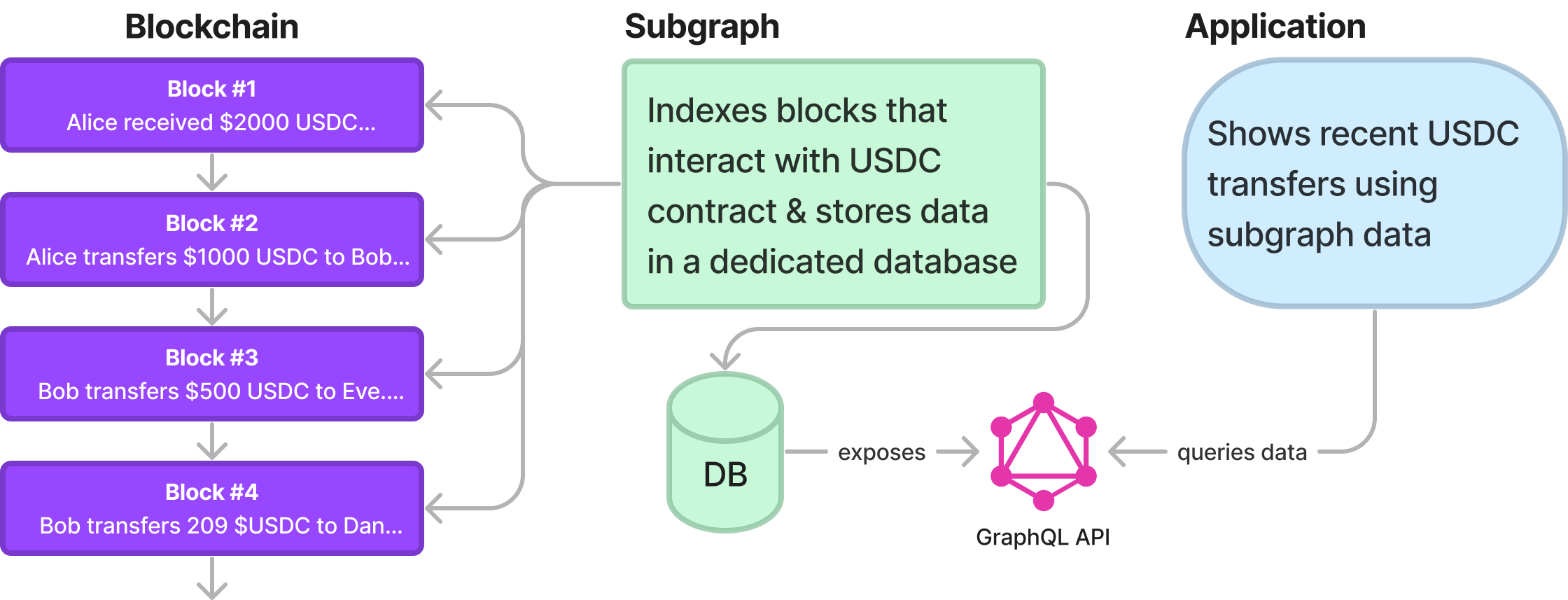
As seen in the diagram above, subgraphs are helpful for indexing complex blockchain data into easily queryable formats, unlocking faster speed and data reliability for end-user and developers alike. The subgraph will consume all of our wanted data for us and set it up in easy-to-query format for us to enjoy as application developers. This subgraph solution becomes even more needed when you need to calculate some aggregate data across all historical blocks, like total inflows ever for a pool.
Want to dive deeper? Check out this comprehensive Alchemy blog post on subgraphs!
Updated over 1 year ago