remove billing information
How can I remove my credit card information from your billing interface?
<br>
Posted by Alex Lemarchand 1 day ago
Blocked signup. Aethir test
I'm trying to log into alchemy to try out the Aethir test node.
However, the message “Blocked signup” appears and the process does not proceed.
I am just a good individual.
Please help me sign up.
My Google Email: [[email protected]](mailto:[email protected])
<br>
Posted by sunho 1 day ago
hCaptcha issue
I can't pass hCaptcha. I got "too many requests" error from it.
I thought this is only my PC problem but my friends in another cities also can't Sigh Up
Please fix that
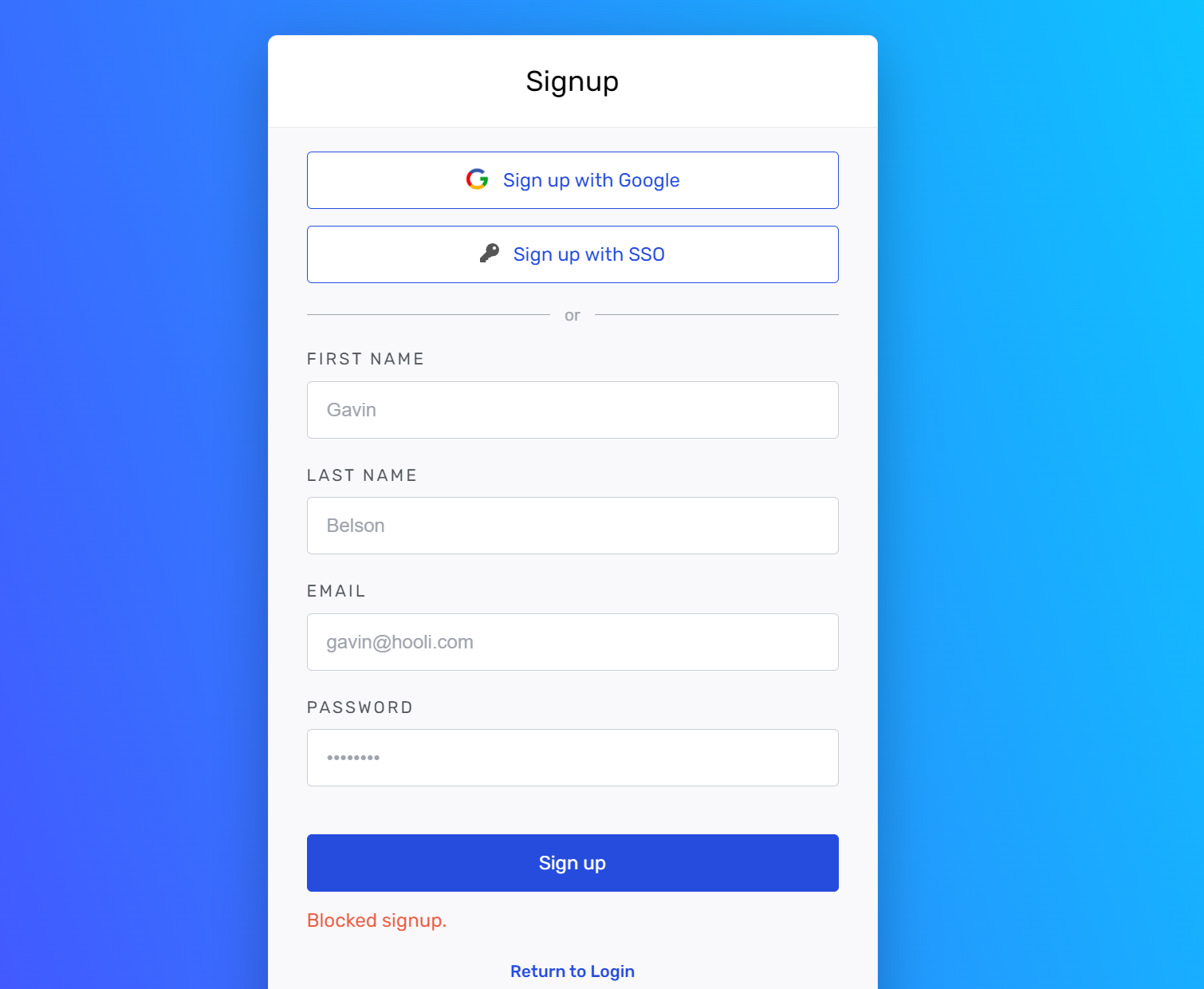
Posted by Roman 4 days ago
Blocked sign up,please help
I signed up with google account but found Blocked sign up.What should i do?
<br>
Posted by 2723579248l 10 days ago
creating a provider for Amoy?
Hi all,
How can we create a provider for the Amoy with "alchemy-sdk": "^2.3.1", Something like ...
This question is related with the question below.
<https://docs.alchemy.com/discuss/62fb458c95bee000365755ab>
const netObj = {
// name: 'polygon-amoy',
name: 'maticamo',
chainId: 80002
}
const provider = new ethers.providers.AlchemyProvider(netObj, apiKey);
Thanks
Akira
Posted by Akira Kudo 11 days ago
Requesting Batch Transaction Limit
We're trying to use Alchemy's Ethereum API service to retrieve Eth and ERC20 txn history and balances. We've noticed that when you send a large batch txn request, sometimes the request gets denied. What is the batch request limit for these transactions?
Posted by Noah S 16 days ago
Webhook is missing
Hello,
<br>
As I try to send multiple transactions at the same time, some webhook messages of transactions are not delivered to my server.
Can you check why I can't receive webhook messages for this case, please?
Thanks,
Posted by Jay Park 17 days ago
Delete Alchemy Account.
Hi. we no longer use the service and I'd like to delete my Alchemy account and the associated team.
Posted by takayuki 18 days ago
Cost pricing data per API call for NFTs: Floor price, sales volume per period, Owners per Collections/NFT Token
Hello,
Could you provide pricing data in compute units for the following NFT API Calls?
1.Floor price
2. Sales volume per period for NFT
3. Owners per Collections/NFT Token
Posted by M 24 days ago
Webhook support for NFT metadata including 30 day volume,Total Holders of Collection and Floor Price
Does alchemy provide a webhook to get live data for 30 day volume,Total Holders of Collection and Floor Price for NFTs?
<br>
Also, which marketplaces for NFTs does alchemy get data from?
Posted by M 24 days ago